
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 다이나믹 프로그래밍
- 웹프로그래밍
- 그리디
- BJ
- 웹 프로그래밍
- mysql
- 네이버 부스트캠프 ai tech
- 정렬
- 브라우저
- 순열 알고리즘
- 소수
- Prim's Algorithm
- request
- 프림 알고리즘
- 부스트코스
- mst
- 웹서버
- SERVLET
- 크루스칼 알고리즘
- dbms
- programmers
- DP
- 프로그래머스
- 벡엔드
- 해시
- jsp
- 정렬 알고리즘
- Kruskal's Algorithm
- 백준
- greedy
- Today
- Total
끵뀐꿩긘의 여러가지
[논문 완전 번역]Fully Convolutional Networks for Semantic Segmentation 본문
[논문 완전 번역]Fully Convolutional Networks for Semantic Segmentation
끵뀐꿩긘 2022. 10. 13. 15:41Fully Convolutional Networks for Semantic Segmentation 논문을 직접 번역해 보았습니다. 문맥이 자연스럽지 않거나 잘못 번역된 부분이 있을 수도 있습니다. 읽으시다가 이상하거나 잘못된 부분들을 말씀해주시면 감사하겠습니다.
- * 부분은 논문에 설명되지 않았지만 논문을 읽으면서 궁금해지거나 필요해져서 제가 추가한 사항들입니다.
- 논문 페이지가 끝날때 +(페이지수)로 표시를 해두었습니다
Fully Convolutional Networks for Semantic Segmentation
Jonathan Long∗ Evan Shelhamer∗ UCBerkeley Trevor Darrell
{jonlong,shelhamer,trevor}@cs.berkeley.edu
Abstract
Convolution 네트워크는 특성들의 계층을 생성하는 강력한 시각 모델입니다.
우리는 Convolutional 네트워크가 그 스스로 end - to -end, pixel - to - pixel로 학습되고,
sementic segmentation의 SOTA(최점단 모델)들을 뛰어넘는 것을 보았습니다.
우리가 말하고싶은 핵심적인 부분은 임의의 size를 가지는 input을 받아,
효과적인 추론 & 학습과 함께 대응되는 사이즈의 출력을 생산하는 "fully convolutional"네트워크를 만들자는 것입니다.
우리는 fully convolution 네트워크의 공간을 정의하고 특정하였습니다.
그리고 공간적으로 밀집한 예측 문제들에 이를 적용하고 이전 모델과 연관하였습니다.
우리는 현대적인 네트워크(Alexnet, VGG, GoogLenet)들을 fully convolution network에 적용하였고, fine-tuning으로 그것들의 학습된 representations들을 segmentation 문제로 전이하였습니다.
그리고 나서 우리는 깊고, 조잡한(coarse) layer에서부터 나온 의미 정보(sementic info.)와 얕고 미세한(fine) layer에서부터 나온 모양 정보(appearance info)를 결합하여 정확하고 디테일한 segmentation을 생성하는 skip architecture을 정의했습니다.
우리의 fully convolutonal 네트워크는 추론 과정이 일반적인 이미지에 대해 1/5 초가 걸리는 동시에 PASCAL VOC(2012년 평균 *IU(Intersection over Union)에서 20% 향상됨), NYUDv2, and SIFT Flow의 segmentation에서 SOTA를 달성했습니다.
*IU(Intersection over Union):
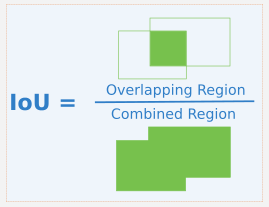
객체 인식 모델의 성능평가 도구
1. Introduction
Convolutional 네트워크는 reconition에서 진보를 이끌고 있습니다.
Convnet은 전체 이미지 분류를 발전시켰을 뿐만 아니라 구조화된 출력(structured output)에 관한 주변 과제들도 진보시켰습니다.
이는 *bounding box object detection, *part and keypoint detection, *local correspondence 분야의 진보를 말합니다.
대략적인 추론에서 정밀한 추론으로 나아가는 자연스러운 다음 단계는 모든 픽셀에서 예측을 하는 것입니다.
이전의 접근 방식은 의미론적(semantic) segementation을 위해 각 픽셀이 객체나 영역의 클래스로 라벨링된 Convnet을 사용했습니다.
하지만 이는 fully convolution 네트워크가 해결하는 문제점을 가지고 있었습니다.
*bounding box object detection, ketpoint detection, local correspondence(부분 정합성)
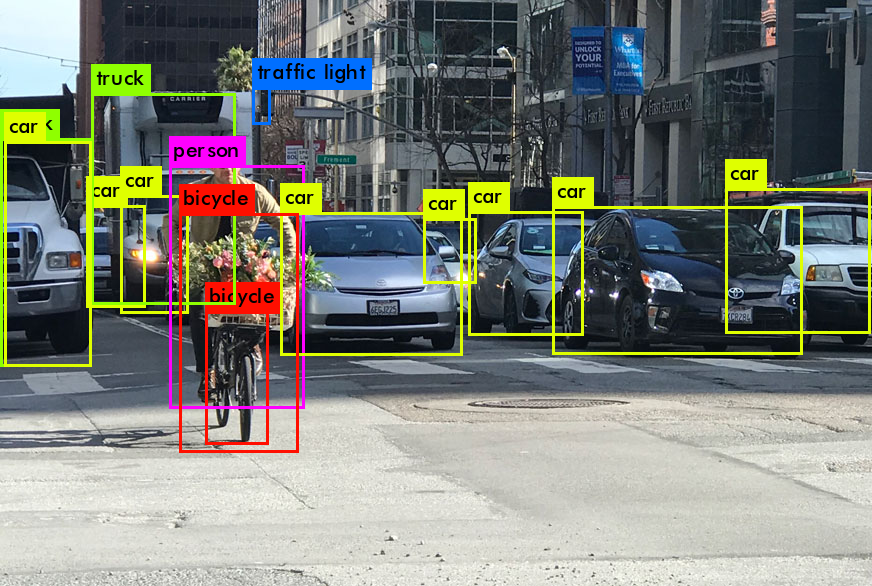


Figure 1. Fully convolutional 네트워크는 semantic segmentation 같은 *dense prediction들을 pixel 당 task로(per-pixel task) 효과적으로 훈련될 수 있습니다.
*dense prediction
CV에서 dense prediction은 각 픽셀의 이미지 레이블을 예측하는 task이다.
우리는 fully convolutional network(FCN)가 sementic segmentation에서 end-to-end, pixels-to-pixels로 훈련되고 다른 장치 없이 sota를 능가한다는 것을 보여주었습니다.
우리가 아는 한에서는 이는 (2)supervised pretraining으로부터 (1) pixelwise prediction을 수행하는 end-to-end FCN을 처음으로 훈련한 것입니다
현재 존재하는 fully convolutional 버전들은 임의의 사이즈의 입력값으로부터 dense output을 예측합니다.
훈련과 추론 모두는 순전파 계산과 역전파로부터 이미지 한번(whole-image-at-a-time)에 수행됩니다.
네트워크 내부의 upsampling 층은 pixelwise 예측과 네트워크 내에서의 subsampled pooling을 가능하게 합니다.
이 방법은 점진적이고 절대적으로 효과적입니다. 그리고 다른 작업들의 필요로 인해 생기는 복잡성을 제외시킵니다.
*Patchwise training은 일반적이지만 fully convolutional trainin의 효율성을 떨어뜨립니다.
우리의 접근법은 *superpixels, propsals, post-hoc rrefinement 같은사전&사후 처리 복잡성을 만들지 않습니다.
우리 모델은 분류 네트워크의 learned representation을 fully convolutional 그리고 fine-tuning을 하는 재해석을 통해 분류 문제에서의 최근 성공을 dense prediction로 전이시킵니다.
그와 대조적으로, 이전의 작업들은 미리 지도 학습되지 않은 작은 convnet을 적용했습니다.
*patchwise training
cnn을 사용한 image segmentation이 대중화되기 이전, 훈련 세트에서 무작위 패치(관심 대상을 둘러싼 작은 이미지영역)을 사용하여 훈련하는 방식이 patchwise training이다.
*superpixel

슈퍼픽셀이란 지각적으로 의미있는 픽셀들을 모아서 그룹화해준 것이다.
즉, 인접해 있는 픽셀들 중에 비슷한 특성(색상 또는 밝기)을 갖고 있는 것끼리 묶어서 거대한 슈퍼픽셀을 만들어준다.
Sementic segmentation은 의미(sematics)와 위치라는 고유의 문제를 마주했습니다
전체적인 정보는 '무엇'(what)을 나타내는 반면 국지적인 정보는 '어디'(where)를 나태냅니다. +(1)
깊은 특성 계층(deep feature hierarchies)는 비 선형적 local-to-global 피라미드에서 의미와 위치를 인코딩합니다.
우리는 깊고 얕은, 의미와 외관 정보를 결합한 특성 스펙트럼을 장점으로하는 skip architecture을 Section 4.2에서 정의하였습니다.(Figure 3을 보세요)
다음 section에서 우리는 깊은 분류 네트워크, FCN 그리고 convnet을 사용한 최근 semantic segmentation을 리뷰하겠습니다.
뒤의 섹션은 FCN 디자인과 dense predicition tradeoff, 우리 모델의 네트워크 내부에서의 upsampling에 대한 소개, 그리고 우리의 실험적인 framework들을 설명합니다.
마지막으로, 우리는 PASCAL VOC2011-2, NYUDv2, and SIFT Flow에서 sota를 입증했습니다.
2. Related work
우리의 접근법은 image classification 분야에서 깊은 네트워크의 최근 성공과 전이학습을 기반으로 합니다.
전이학습은 여러 시각적 인식 과제들에서 증명되었고,다목적의 분류 모델에서 detection, *instance and semantic segmantation 분야도 증명되었습니다.
우리는 이제 분류 네트워크를 직접적으로 semantic segmentation의 dense prediction에 맞게 재설계하고 fine-tune 하겠습니다.
우리는 이 framework에서 FCN의 오래된, 최근의 이전 모델들의 성능들을 표로 만들었습니다.
*instance and semantic segmantation
segmentation은 이미지의 pixel 수준에서 각 영역이 어떤 의미를 갖는지 분리하는 방법이다.
segmentation은 instance segmentation과 semantic segmentation 두 종류로 구분할 수 있다.
- instance segmentation
각 객체 별로 사진 분할
- semantic segmentation
각 의미 별로 사진 분할
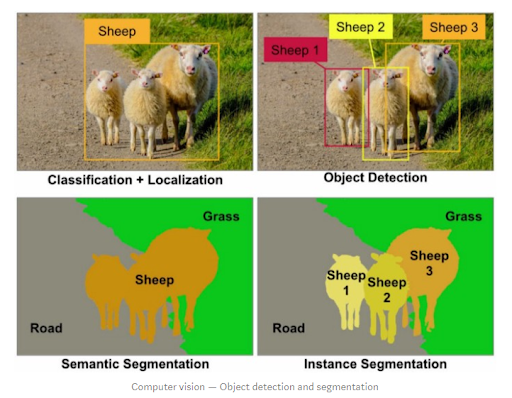
instance segmentation은 각각의 객체를 분리해서 분류하지만 semantic segmentation은 그렇지 않다.
Fully Convolutional networks
우리의 지식에서, convnet을 임의의 사이즈 input으로 확장하는 idae는 문자열과 숫자들을 인식하기 위해서 classic LeNet을 확장한 Matan et al에서 처음 나왔습니다.
그들의 네트워크가 1차원 입력 문자열에 제한되어있었기 때문에 Matan et al은 그들의 출력값을 얻기 위해서 Viterbi 디코딩을 사용하였습니다.
Wolf and Platt은 convnet 출력값을 우편 주소 블럭의 4 꼭짓점을 나타내는 detection score의 2차원 맵으로 확장했습니다.
이런 역사적 작업들은 detection에서 추론과 학습을 fully convolutional하게 진행했습니다.
Ning et al.은 fully convolutional 추론으로 C. elegans tissues 문제를 다중 클래스 segmentation을 사용한 convnet으로 정의하였습니다.
Fully convolutional 계산은 또한 최근의 층을 많이 가지고 있는 네트워크에 의해서 개척되었습니다.
Sermanet et al의 Sliding window detection, Pinheiro and Collobert의 semantic segmentation 그리고 Eigen et al.의 image restoration은 fully convolutional 추론을 수행했습니다.
Fully convolutional 훈련은 희귀하지만T ompson et al.에 의해 end-to-end 부분 detector와 포즈 평가를 위한 spatial model에 효율적으로 사용되었습니다.
하지만 그들은 이 방법을 설명하거나 제시하지는 않았습니다.
대안으로, He et al는 특성을 추출하는 분류 네트워크에서 non - convolutional 부분을 제거했습니다.
그들은 분류를 위한 지역적이고 길이가 고정된 특성을 생성하기 위해서 proposal과 spatial pyramid polling을 결합했습니다.
그것들은 빠르고 효율적이지만 end-to-end로 학습되지 않습니다.
Dense prediction with convnets
최근 여러개의 작업들은 convnet을 dense precition 문제에 적용합니다.
이는 Ning et al, Farabet et al.,Pinheiro and Collobert의 semantic segmentation, Ciresan et al의 전자현미경 경계 예측,
Ganin and Lempitsky의 by natural images by a hybrid convnet/nearest neighbor model, Eigen et al의image restoration and depth estimation를 포함합니다.
이러한 접근의 공통적인 요소들은 아래와 같다.
- receptive fields와 용량을 제한시킨 작은 모델
- patchwise training
- superpixel projection, random field regularization, filtering, or local classification 같은 이미지 사전처리
- dense output의 input shifting and output interlacing(비월 주사 방식)
- 다중 크기의 피라미드 처리
- 포화 tanh 비선형성
- 앙상블
우리의 모델은 이러한 장치들을 사용하지 않는다.
하지만 우리는 patchwise training과 shift-and-stitch dense ouput을 FCN의 관점에서 사용하였습니다.
우리는 또한 네트워크 내부에서의 upsampling에 대해 논의했습니다.
현재 존재하는 방법들과는 달리, 우리는 전체 이미지 입력값과 전체 이미지 *ground thruth로부터 간단하고 효과적으로 배울 수 있도록 미리 지도학습되고 fine-tining된 fully convolutional 이미지 분류기를 사용하여 깊은 분류 architecture를 적용하고 확장하였습니다.
Hariharan et al. and Gupta et al.도 비슷하게 sementic segmentation에 깊은 분류 모델들을 적용했습니다.
하지만 이를 hybrid proposal-model에서 수행하였습니다.
이러한 방법은 fine-tune된 R-CNN 시스템을 sampling bounding box 그리고 region proposals를 위한 detection,semantic segmentation, and instance segmentation에 적용하였습니다.
이중 어떤 방법도 end-to-end로 학습되지 않습니다.
그들은 PASCAL VOC and NYUDv2에서 각기 sota를 달성했습니다.
그렇기에 우리는 Section 5에서 우리의 독립적이고 end-to-end FCN을 그들의 semantic segmentation 결과에 직접적으로 비교하였습니다.
*ground truth
ground truth는 학습하고자하는 데이터의 원본 혹은 실제 값을 의미한다. == 정답값

3. Fully convolutional networks
connvnet에서 데이터의 각 층은 h*w*d의 3차원 배열입니다. (h와 w는 공간적 차원, d는 특성 또는 채널 차원)
첫번째 층은 픽셀사이즈가 h*w이고, 색깔 채널이 d인 이미지입니다.
높은 층의 위치는 경로가 연결된(path-connceted to) 이미지의 위치에 대응되며 이를 receptive field라고 합니다.
Convnet은 translation invariance를 기반으로 합니다.
그것의 기본적인 구성요소(convolution, pooling, and activation functions)들은 input region에서 작동하고, 상대 공간 좌표(relative spatial coordinates)에만 영향을 받습니다.
$X_{ij}$는 특정 층에서 $(i,j)$에 위치한 데이터 벡터를 나타냅니다. +(2)
다음 layer에 대해 $y_{ij}$를 사용하는 경우 이 함수는 출력 $y_{ij}$를 다음과 같이 계산합니다.
$$y_{ij} = f_{ks}(\{x_{si+\gamma i, sj + \gamma j}\}_{0\ge \gamma i,\gamma j \ge k})$$
$k$는 커널 사이즈 $s$는 stride 또는 subsampling를 의미합니다.
그리고 $f_{ks}$는 layer type을 결정합니다: conv 또는 avg pooling의 행렬곱, 활성화 함수의 비선형적 요소별 계산, 그리고 다른 타입의 층들을 위한 연산들
이러한 함수적 형태는 kernel size와 stride에 관련된 변환 규칙 하에서 유지됩니다.
$$f_{ks} \circ g_{k^{'}s^{'}} = (f \circ g)_{k^{'} + (k-1)s^{'}, ss^{'}}$$
일반적인 deep 네트워크가 일반적인 비선형 함수를 계산하는 것에 반해, deep filter 또는 fully convolutional network는 비선형 filter를 계산한다.
FCN은 자연적으로 입력값이 어떤 사이즈이든 작동한다.
그리고 대응하는 공간 차원을 가진 출력값을 생성한다.
FCN으로 구성된 real-valued loss function은 과제를 정의한다.
만약 loss func.이 마지막 층에서 모든 공간 차원을 다 더해버린다면,$\mathit{l}(x;\theta) = \sum_{ij}\mathit{l}^{'}(x_{ij};\theta)$ 그것의 gradient는 각각의 공간적 구성요소들의 gradient의 합입니다.
따라서 전체 이미지에 대해서 $\mathit{l}$을 sgd로 구한 gradients는 모든 마지막 layer의 receptive field를 미니배치로 하여 $\mathit{l}^{'}$를 sgd로 구한 graients와 같다.
이러한 receptive filed가 상당히 겹칠때, 각각을 patch-to-patch로 계산하는 것보다 layer-by-layer로 순방향 계산과 역전파를 하면 더 효율적이게 된다.
우리는 다음으로 어떻게 분류 네트워크를 coarse ouput map을 생성하는 fully convolutional nets로 바꾸는지 설명하겠습니다.
pixelwise 예측에서, 우리는 이러한 coarse ouput을 전에 있는 pixel들과 연결할 필요가 있다.
Section 3.2가 이러한 trick인 fast scanning을 설명하고 있다.
우리는 그것을 동등한 네트워크 변경으로 재해석함으로써, 이러한 trick에 대한 통찰력을 얻을 수 있다.
효율적이고 효과적인 대안으로, 우리는 Section 3.3에서 upsampling을 위한 deconvolution layer를 소개한다.
Section 3.4에서는 우리는 patchwise sampling에 대해 고려하고 Section 4.3에서는 전체 이미지에 대한 훈련 방식이 빠리고 효과적이라는 증거를 제시합니다.
3.1. Adapting classifiers for dense prediction
전형적인 LeNet, AlexNet 그리고 그것들의 더 깊은 성공장들을 포함한 recognition 네트워크에서는 표면적으로 고정된 사이즈의 입력값을 받았고, 공간적이지 않은 출력값을 내보냈습니다.
이러한 네트워크들의 fully connected layer 차원을 고정했고 공간적 좌표를 버렸습니다.
하지만 이러한 fully connected layer는 그것들의 전체 이미지 region을 커러하는 convolution으로 바라볼 수도 있습니다.
그렇게 하면, 모든 크기의 입력과 분류 맵 출력을 소화하는 convolution network로 변환됩니다.
이러한 변환은 Figure 2에 그림으로 그려져 있습니다.

Figure 2. fully connected layer를 convolution layer로 바꾸는 것은 분류 네트워크가 heatmap을 출력값으로 낼 수 있게 해준다. layer와 spatial loss를 더하는 것은(Figure 1처럼) end-to-end dense 학습을 위한 효율적인 기계를 생성한다.
게다가, 결과 맵이 특정 입력 패치들의 원래 네트워크의 evalutation과 동등하지만, 계산은 해당 패치의 겹치는 영역에 대해 크게 상각(보상하여 되돌려 준다 갚아준다는 의미)된다.
예를 들어, AlexNet이 227*227이미지의 분류 점수를 계산하는데에 1.2ms(일반적인 GPU에서)가 걸렸지만, full convolution 네트워크는 500*500이미지에 대해서 10*10 그리드의 출력값을 내놓는데 22ms 이 걸렸다.
이는 일반적인 접근법보다 5배 이상 빠르다는 것을 의미한다.
이러한 convolutionalized 모델의 공간적인 출력 맵은 그들에게 semantic segmentation같은 dense 문제들에 대해 자연스러운 선택권을 준다.
ground truth가 출력 셀들에 대해 모두 존재한다면, 순전파와 역전파는 모두 간단해지며, 둘다 convolution과 공격적인 optimization의 고유한 계산상의 이득을 볼 수 있다.
상응하는 alexnet의 역전파 시간은 하나의 이미지에 대해서 2.4ms, fully convolutional 10*10 출력 맵에 대해서 37ms이 걸렸다.
그 결과 순방향 전파와 비슷하게 속도까 빨라졌다.
우리의 분류 네트워크를 fully convolution layer로 재해석하는 것은 입력값이 어느 사이즈이든 출력 맵을 생상할 수 있었지만, 출력 차원은 일반적으로 *subsampling에 의해 축소된다.
분류 네트워크는 필터의 크기를 작게 유지하고 계산상의 요구사항이 합리적이도록 subsample한다.
이것은 이러한 네트워크의 fully convolutional 버전의 출력을 coarsen하여 입력 크기에서 출력 창지의 receptive field의 pixel stride만큼 감소시킨다.+(3)
*subsampling
데이터의 크기를 줄이는 것을 의미한다.

3.2. Shift-and-sitch is filter rarefaction
Dense prediction은 입력값의 이동된(shifted) 버전으로부터 출력값을 바느질하는(stitching) 것으로 coarse output으로부터 얻어질 수 있다.
만약 f 요소에의해서 출력값이 downsample 된다면, 입력값 x 픽셀들을 오른쪽으로 그리고 y 픽셀들을 밑으로 이동한다(shift)
$$(x,y) s.t. 0 \ge x,y \ge f$$ (# s.t.은 such that 그러한 것을 만족시키는)
이러한 $f^2$ 입력 각각을 처리하고 출력을 *interlace하여 예측이 receptive field의 중앙에 있는 픽셀에 대응하도록 한다.
*interlace
인터레이스(Interlaced)
인터레이스 방식은 하나의 프레임에 수평 주사선을 1개 간격으로 뛰어 넘어 주사하는 방식입니다. 홀수열과 짝수열을 주사한 것을 필드라고 불리며, 두 필드를 합쳐 하나의 완전한 영상을 만들어 완전한 하나의 프레임이 구성됩니다.

프로그레시브(Progressive)
프로그레시브 스캔의 경우 아래 그림과 같이 완전한 한 장의 프레임 하나 하나를 연속적으로 보여주기 때문에 고화질 화면을 감상할 때 유리합니다.

이러한 변환을 수행하는 것은 $f^2$라는 요소에 대해 비용을 증가시키지만, a trous algorithm으로 알려져있고, 효과적으로 동일한 결과를 얻을 수 있는 잘 알려진 트릭이 존재한다.
Convolution 또는 Pooling 층, 입력값 stride $s$ 그리고 다음 convolution층의 필터 가중치 $f_{ij}$(관계없는 feature 차원 생략)를 고려합니다.
하위 layer의 input stride를 1로 설정하면 출력이 s만큼 upsampling 됩니다.
하지만, 원래 필터를 upsampled 출력값과 엮는 것은 shift-and-stitch와 같은 결과를 내놓지 못합니다.
왠냐하면, 원래 필터는 단지 입력값의 줄어든 부분(현재는 upsample된)만 보기 때문입니다.
트릭을 재현하기 위해서는, 필터를 다음과 같이 확대하여 희박하게 만들어야 한다.

(i랑 j는 zero-based다.)
trick의 전체 네트워크 출력값을 재생성하려면 모든 subsampling이 제거될때까지 필터 확대를 layer-by-layer로 반복해야한다.
(실전에서는, 이것은 upsampled 입력값의 subsampled된 버전을 처리함으로써 효율적으로 수행될 수 있다.)
네트워크에서 subsampling을 줄이는 것은 tradeoff이다: 필터가 더 상세한 정보를 보지만, 더 작은 receptive field를 가지고 계산 시간이 오래걸린다.
shift-and-stitch trick은 다른 종류의 tradeoff이다: 출력값은 필터의 receptive field 크기를 줄이지 않고 더 조밀하지만, 필터는 원래 디자인보다 더 미세한 규모의 정보에 접근하는 것이 금지된다.
우리가 이 트릭으로 예비 실험을 했지만, 우리는 모델이 이 방법을 사용하지 않을 것이다.
우리는 다음 섹션에서 설명되는 특히 나중에 설명될 skip layer와 합성하는데에 있어서더 효과적이고 효율적인 학습방법을 upsampling을 통해 찾았다.
3.3. Upsampling is backwards strided convolution
coarse outputs을 dense pixels로 잇는 다른 방법은 보간(interpolation)입니다.
예를 들어 간단한 *bilinear interpolation은 입력과 출력 셀들의 연관된 위치에만 영향을 받는 linear map에 의해 가장 가까운 4개의 입력으로부터 각각의 출력값 {y_{ij}}를 계산할 수 있다.
어떤 의미에서 인자 f를 사용한 upsampling은 {\frac{1}{f}}의 strdie를 갖는 convolution이다.
f가 적분인한, upsample을 하는 자연스런 방법은 출력값 stride f로 backwards convolution하는 것이다.(때때로 deconvolution으로도 불린다).
이러한 연산은 단순히 convolution의 순방향과 역방향 계산을 뒤집으면 되기 때문에 구현하기 명확하다.
게다가 upsampling이 pixelwise loss로 역전파되어, 네트워크 내부적으로 end-to-end 학습을 수행할 수 있다.
*interpolation
deconvolution 필터가 고정될 필요가 없고 학습될 수 있다는 것을 주목해라 (e.g. bilinear upsampling )
deconvolution 층과 활성화 함수의 stack은 심지어 비선형적 upsampling을 학습할 수 있다.
우리의 실험에서, 네트워크 내부적인 upsampling은 dense prediction에서 빠르고 효율적이다.
우리의 최고 성능 segmentation architecture는 Section 4.2에서 정제된(refined) 예측을 위해 upsampling하는 방버블 학습한다.
3.4. Patchwise training is loss sampling
확률적 최적화(stochastic optimization)에서 gradient 계산은 훈련 분포에 의해 수행된다.
patchwise training과 fully convolution training 둘다는 연관된 연산 효율성이 overlap과 미니배치 사이즈에 달려있지만, 아무 분포나 생성하도록 만들어질 수 있다.
전체 이미지를 fully convolutional training하는 것은 각각의 배치가 이미지(또는 이미지 모음) loss 단위의 모든 receptive field로 구성된 patchwise training과 동일하다.
이것이 패치에 대한 uniform sampling보다는 효율적이지만, 그것은 가능한 배치의 숫자를 줄인다.
하지만, 이미지에서 패치에 대해 랜덤으로 고르는것이 아마 간단히 복구할 것이다.
loss를 spatial term의 랜덤하게 샘플된 하위집합으로 제한하는 것은 패치들을 gradient 연산에서 제외시킨다.
만약 kept patches가 아직 상당히 overlap 되어있다면, fully convolutional computation이 아직 훈련의 속도를 높일 수 있을 것이다.
만약 gradient가 여러번의 역전파로 쌓여있다면, 배치들은 여러 이미지들로부터 patch들을 포함할 수 있다.
patchwise training으로 sampling하는 것은 클래스 불균형을 교정할 수 있고, dense patch들으니 공간적 상관관계를 줄일 수 있다.
fully convolutional training에서 클래스 불균형은 loss를 가중화하는 것으로 완화할수 있고, loss sampling 또한 공간적 상관관계를 설명하는 요소로 사용될 수 있다.
우리는 Section 4.3에서 Sampling에 관해 훈련하는 것을 탐구했고, patchwise training이 dense prediction에 더 빠르거나 더 나은 수렴을하지 않는다는 것을 발견했습니다.
Whole image training이 더 효과적이고 효율적입니다.
4. Segmentation Architecture
우리는 ILSVRC 분류기를 FCN으로 바꾸었고 dense prediction을 수행하고 내부적인 upsampling과 pixelwise loss를 가지는 모델로 증강했다.
우리는 fine-tuning으로 segmentation에 대해 훈련했다.
그다음 우리는 예측을 구체화하기 위해 coarse, semantic and local, appearance 정보를 가지는 새로운 skip architecture를 만들었다.
이러한 조사로, 우리는 PASCAL VOC 2011 segmentation challenge에서 훈련하고 검증했다. +(4)
우리는 픽셀별(per-pixel) *multinomial(다항식의) logistic loss를 사용하여 훈련했고, 배경을 포함하여 모든 클래스에 적용되는 평균을 사용하여 mean pixel intersection over union(IoU)이라는 정석적인 평가지표로 검증하였다.
*multinomial logistic loss
cross entropy와 같은 것을 의미하는 것 같다
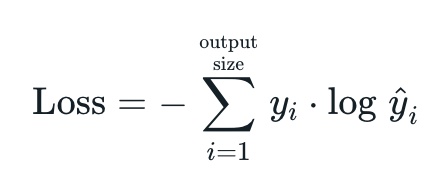
4.1 From classifier to dense FCN
Section 3에서 우리는 증명된 분류 architecture들을 convolutionalizing하며 시작했다.
우리는 ILSVRC12에서 우승한 AlexNet, VGG와 ILSVRC14에서 우승한 GoogLeNet을 고려했다.
우리는 이 과제에서 19층 네트워크와 동일한 VGG 16을 선택했다.
GoogLeNet에 있어서, 우리는 단지 마지막 층의 loss만을 사용했고, 마지막 avg pool 층을 삭제함으로써 성능을 향상시켯다.
우리는 각 네트워크의 마지막 층을 삭제했고, fc(fully connected 층)을 convolution으로 대체했다.
우리는 각각의 coarse ouput 위치에서 각각의 PASCAL 클래스 (배경을 포함한다) 점수를 예측하기 위해서 21개 채널을 가진 1*1 convolution을 추가했다.
그리고 나서 Section 3.3에서 설명한 대로 coarse output을 pixel dense output으로 bilinearly upsample하기 위해 deconvolution 층을 사용하였다.
Table 1은 예비 validation 결과와 네트워크 각각의 기본적인 특성을 비교한 것이다.
최소 175 epochs 이상에서 수렴후 가장 최고의 결과를 적어두었다.
분류에서 segmentation으로 fine-tuning하는 것은 각각의 네트워크에 합리적인 예측을 준다.
심지어 가장 최악의 모델도 sota performance의 75%까지는 보였다.
segmentation-equippped VGG net (FCN-VGG16)은 validation에서 평균 56.0 IU 테스트에서 52.6으로 벌써 sota로 보인다.
학습 관련 디테일 부분은 Section4.3에 있다.
비슷한 분류 정확도와는 다르게, GoogLeNet 구현은 이러한 segmentation 결과에 맞지 않았다.
4.2 Combining what and where
우리는 segmentation에서 특성 계층을 결합하는 새로운 fully convolutional net (FCN)을 정의했다.
그리고 결과에 대한 공간적 precision 또한 정의했다.
Figure 3.을 봐라
fully convolutionalized 분류기가 4.1에서 보여준 것처럼 segmentation에 fine-tuned될 수 있고, 현재 정석적인 metric보다 심지어 높은 점수를 보이지만, 그들의 출력값은 만족스럽지 못하게 coarse(조잡)하다.(Figure 4.을 봐라)
마지막 예측에서의 32픽셀 stride는 upsampled output에서 디테일의 정도를 제한한다.
Table 1. 우리는 세개의 classification convnets를 segmentation으로 적용하고 확장하였다.
우리는 PASCAL VOC 2011의 validation set로 intersection over union(IOU)의 평균 performance값과 NVIDIA Tesla K40c의 500 × 500 input을 20번 시행하는 평균 추론 시간으로 서로를 비교하였다.
우리는 dense prediction(파라미터 층의 개수, output unit의 receptive field 크기, 네트워크 안에서의 coarsest stride)을 고려하여 개조된 architecture들을 자세히 기술해 두었다.
(이러한 숫자들은 고정된 learning rate에서 얻어진 가장 최고의 performance이며, 최고점이 아닐 수도 있다.)

우리는 세밀한 stride로 마지막 예측 layer를 lower layer와 연결하면서 이 문제를 해결했다.
이것은 낮은 layer를 높은 것들로 skip 햐주면서 *line topology을 *DAG로 바꿔준다.
그들이 적은 픽셀을 보면 더 미세한 규모의 예측이 더 적은 층들을 필요로 한다, 그러므로 그들이 얕은 네트워크의 output으로부터 결과값을 만들어내는 것은 합리적이다.
fine layer와 coarse layer를 합치는 것은 모델이 global structure를 고려하며 local predictions을 만드는 것을 의미한다.
Florack et al의 multiscale local jet analogy에 의해서 우리는 비선형적 지역 측성 계층(nonlinear local feature hierarchy)을 deep jet라고 부른다.
*line topology
토폴로지는 컴퓨터 네트워크의 요소들(링크, 노드 등)을 물리적으로 연결해 놓은 것, 또는 그 연결 방식을 말한다
*DAG
유향 비순환 그래프
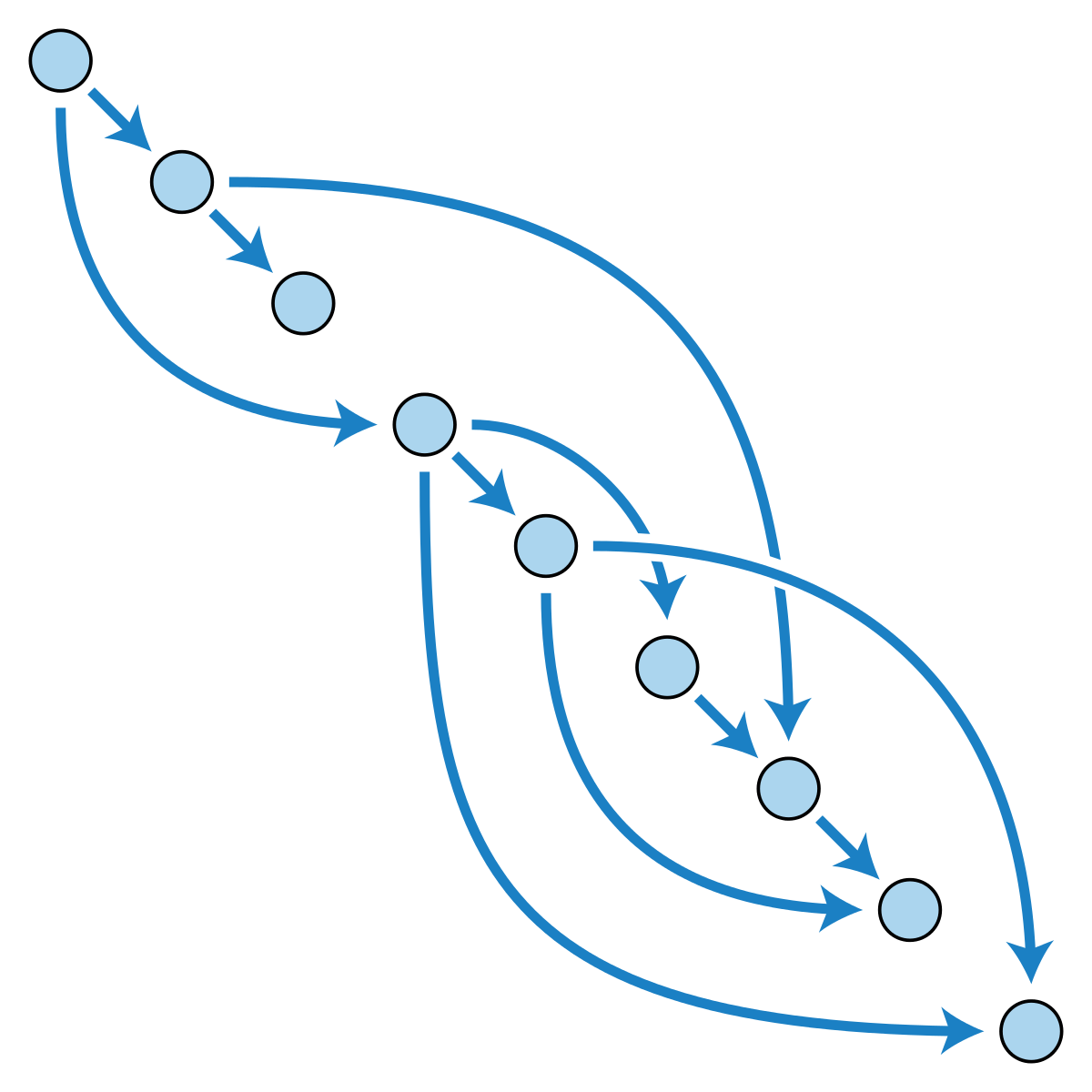
우리는 처음으로 16 픽셀 stride층에서부터 output stride를 반으로 나눠 예측했다..
우리는 추가적인 class prediction을 위해서 1*1 convolution layer를 pool4의 위에 더했다.
예측값과 출력을 합성한 후에 stride 32에서 2* upsampling 층을 추가하고 두 에측을 합산하여 conv7위에 올렸다.
우리는 2X upsampling을 bilinear interpolation으로 초기화 하였지만, Section 3.3 처럼 파라미터들이 learnable하게 만들어두었다.
마지막으로 stride 16 prediction은 이미지 크기로 upsample된다.
이게 FCN-16이다.
FCN-16은 end-to-end로 훈련되고, FCN-32의 파라미터들로 초기화된다.
pool 4에서 사용되는 새로운 파라미터는 zero-initialized되었다. 그러므로 네트워크는 변경되지 않은 예측에서 시작한다.
learning rate은 100마다 감소하였다.
skip net에 대해 배우는 것은 validation set의 IU를 3.0에서 62.4로 증가시켰다.
Figure 4.는 출력의 미세구조 개선에 대해 보여준다.
우리는 pool 4 계층에서만 학습하는 fusion(성능 저하)과 단순히 추가 링크를 더하지 않고 learning rate만 줄인 경우(출력 품질 향상 없이 미미한 성능 향상)을 비교하였다.
우리는 이런 방식으로 계속하여 pool4 and conv7의 예측을 합친 것을 2X upsampling한 것을 pool3의 예측과 합친 FCN-8을 만들었다. +(5)
우리는 IU 평균값 62.7이라는 약간의 추가적 성능 향상을 얻을 수 있었다 그리고 출력 그림의 세부적이고 매끄러운 약간의 향상을 볼 수 있었다.
이 시점에서 우리의 fusion improvements는 대규모 정확성을 강조하는 IU metric과 시각적인 부분 모두 감소를 맞이했으므로 더이상 낮은 층에서 fusing을 하지는 않았다.

Figure 4. fully convolutional nets을 다른 stride를 가진 층의 fusing information으로 정제하는 것은 segmentation detail을 향상시켜준다.
처음부터 3개의 이미지들은 32, 16, and 8 pixel stride nets의 결과물이다.
Table 2. PASCAL VOC2011 validation 데이터셋에 따른 skip FCN 비교.
마지막 layer가 fine-tuned된 FCN32s-fixed를 제외하고 모든 학습은 end-to-end로 수행되었다.
FCN32s은 FCN-VGG16으로 stride를 강조하기 위해 이름만 바꾸었다.

Refinement by other means
pooling layer의 stride를 줄이는 것은 finer prediction을 얻는 가장 직접적인 방법이다.
하지만 VGG16-based net에서 이것은 문제가 있다.
Pool 5층이 stride 1을 갖도록 설정하는 것은 receptive field 크기를 유지하기 위해서 convolutionalized fc6가 14 × 14 커널 크기를 필요로 한다는 것을 의미한다.
게다가 그들의 computational cost에 대해, 그런 큰 필터를 훈련시키는 것은 어려움이 있다.
우리는 pool 5이상의 층에서 작은 필터를 사용하도록 재설계하는 시도를 하였지만, 비교적인 성능에서 성공을 하지 못했다.
하나의 가능한 설명은 높은 층의 ImageNet-trained weights의 초기화가 중요하였기 때문이다.
finer predictions를 얻는 다른 방법은 section 3.2에서 설명한 shiftand-stitch trick를 사용하는 것이다.
표현력이 줄어든다는 점에서, 우리는 이 방법의 개선 비율이 ayer fusion에 비해 나쁘다는 것을 발견했다.
4.3 Experimental framework
Optimization
SGD with momentum으로 훈련했다.
우리는 20개의 이미지 크기의 미니배치를 사용했고, FCN-AlexNet, FCN-VGG16, and FCN-GoogLeNet에서 각각 $10^{-5}, 10^{-4}, 5^{-5}$로 learning rate를 고정하고 line search로 골랐다.
momentum은 0.9, weight decay는 $5^{-4}, 2^{-4}$ 그리고, bias에 대해서는 learning rate를 두배로 하였다.
하지만 learning rate를 제외한 다른 파라미터들에 대해서는 훈련이 둔감했다.
우리는 class scoring convolution layer를 zero-initialize하여, 더 나은 성능이나 더 빠른 수렴을 산출하지 않는 무작위 초기화를 찾는다.
Dropout은 원래 분류기에 있던 곳에 추가되어 있다.
Fine-tuning
우리는 전체 층에 대한 역전파로 모든 층을 fine-tune하였다.
Table 2에서 비교한 것처럼 output classifier만 fine-tune 하는 것은 전체를 fine-tune한 것의 70% 성능 밖에 내지 못한다.
Training from scratch(처음부터 학습하는 것)은 base classification nets이 학습하는데 필요한 시간을 고려할 때 실현적이지 않다.
하나의 GPU와 coarse FCN-32s version에서 Fine-tuning은 3일이 걸렸다.
그리고 FCN-16s과 FCN-8s versions으로 올리는데 하루씩 더 걸렸다.
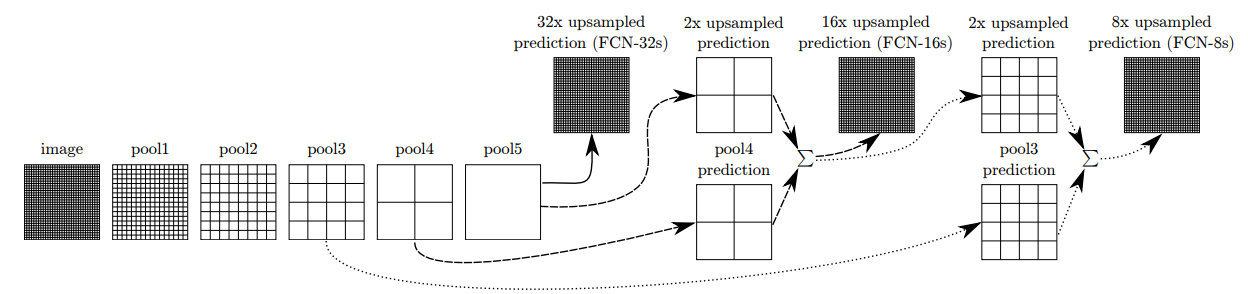
Figure 3.
DAG 네트워크는 높은 층으로부터 coarse하고 낮은 층으로부터 fine한 정보들을 합치면서 훈련된다.
layer들은 상대적 공간 조밀도(coarseness)를 나타내는 그리드로 표현된다.
pooling 과 prediction layers만 보여진다.
fully connected layers를 포함한 중간의 convolution layer들은 생략되어있다.
FCN-32의 실선(solid line): Section 4.1에 설명되어 있는 single-stream net 한번에 stride 32로 prediction step을 맞춰주었다.
FCN-16의 점선(dashed line): 높은 수준의 의미 정보를 유지하면서 pool4 층과 마지막 층의 예측을 stride 16으로 합쳐서 더 미세한 디테일들을 예측하는 네트워크를 만들었다
FCN-16의 점선(dotted line): pool3에서의 예측을 추가하여 stride 8로 합쳐, 더 정확하게 예측하였다.
Patch Sampling
Section 3.4에서 설명한 것처럼, 우리의 전체 이미지 훈련은 각각의 이미지를 크고 overlapping patch들의 규칙적인 그리드에 효율적으로 배치한다. +(6)
대조적으로, 이전 연구는 전체 데이터 세트의 거쳐 무작위로 패치를 샘플링하여 잠재적응로 수렴을 가소고하할수 잇는 더 높은 분산 배치를 초래한다.
우리는 앞서 설명한 방식으로 손실을 공간적으로 샘플링하여 이러한 trade-off를 연구하며 확률 1-p로 각 최종 layer 셀을 무시하도록 독립적으로 선택한다.
효과적인 batch size를 바꾸는 것을 피하기 위해서, 우리는 동시에 배치마다의 이미지 개수를 1/p에 읳해 증가시켰다.
convolution의 효율성에 의해, 이 형태의 rejection sampling은 충분히 큰 값의 p에 대한 patchwise training보다 빠르다.
Figure 5는 이러한 형태의 sampling에 대한 수렴 효과를 보여준다.
우리는 whole image training에 비해 sampling 방법들이 유의미한 효과를 보여주지 못한다는 것을 발견했다.
오히려 배치당 고려해야하는 영상의 수가 더 많기 때문에 시간이 훨씬 더 많이 걸린다.
그래서 우리는 unsampled, whole image training을 선택했다.

Figure 5.
전체 이미지로 훈련하는 것은 sampling patches한 것만큼 효과적이지만, 효율적인 데이터 사용으로 더 빠른 수렴 결과를 보인다.
왼족은 고정된 예상 배치 사이즈의 수렴률에 대한 sampling 효과를 보연준다.
오른쪽은 *wall time 별로 동일한 결과를 표현한다.
*wall time
Wall-clock Time(Response time, Elapsed time) - 한 task를 수행하는데 걸린 전체 시간을 뜻한다. disk access, I/O 활동 , OS overad 기타등등 모두 포함한 시간이다. 결국 System performance 를 결정한다.
Class Balancing
Fully convolutional training은 weighting or sampling the loss로 클래스의 균형을 맞출 수 있다.
라벨인 약간 불균형하지만(약 3/4는 배경) 클래스 밸런싱은 불필요하다.
Dense Prediction
점수는 네트워크 안으 deconvolution layer에 의해 입력 차원으로 upsample된다.
최종 layer deconvolution filter는 bilinear interpolation으로 고정되고, 중간의 upsampling layers는 bilinear upsampling으로 초기화되어 학습된다.
Shift-andstitch 나 filter rarefaction equivalent는 사용되지 않는다.
Augmentation
우리는 training dataf를 randomly mirroring과 예측의 가장 coarsest scale과 같은 32픽셀까지 jittering으로 변환해보았으나 유의미한 결과는 얻지 못했다.
More Training Data
Table 1.에서 사용되었고, Hariharan et al.에 의해 1112개의 이미지가 라벨링 된 PASCAL VOC 2011 segmentation challenge training set는 이전 sota를 훈련하는데 사용된 훨씬 더 큰 8498 PASCAL training image set을 수집했다.
이 training dats는 FCNVGG16의 validation score를 mean IU에서 3.9 향상시켜 59.4로 만들었다.
Implementation
모든 모델들은 Caffe에서 a single NVIDIA Tesla K40c으로 훈련되고 평가되었다.
모델들과 코드는 open-source로 열릴 것이다.
5. Results
우리는 PASCAL VOC, NYUDv2, and SIFT Flow의 semantic segmentation와 scene parsing에서 FCN을 테스트했다.
이러한 과제들이 역사적으로 objects and regions의 사이로 구분되지만, 우리는 이 둘 다를 pixel prediction으로 여길 것이다.
우리는 이러한 데이터셋으로 FCN skip architecture를 평가하고, NYUDv2의 *multi-modal 입력으로 확장하고, SIFT Flow의 semantic and geometric label의 multi-task prediction 으로 확장하였다.
*multi-modal
시각, 청각, 감각 등의 다양한 모달리티를 동시에 받아들이고 사고하는 AI 모델
Metrics
일반적으로 semantic segmentation과 scene parsing 평가에 사용되고 pixel accuracy와 IU를 측정하는 4개의 평가 방법을 사용하였다.
$n_{cl}$개의 다른 클래스가 있을 때, $n_{ij}$를 i 클래스로 예측된 j 클래스의 픽셀이라하고, $t_i = \sum_{j}n_{ij}$ 가 i 클래스의 총 개수라고 하자.

PASCAL VOC
Table 3.은 PASCAL VOC 2011 and 2012의 test set에 대한 이전 sota(SDS, R-CNN)와 비교한 FCN-8의 성능을 보여준다.
우리는 20%의 relative margin의 mean IU를 최고 결과로 얻었다.
추론 시간을 (convnet only)114배, (overall) 전체적으로는 286배 줄였다.

Table 3.
fully convolutional net은 PASCAL VOC 2011 and 2012 test sets에서 상대적으로 20% 성능의 향상을 보였고, 추론시간을 줄였다. +(7)

Table 4.
NYUDv2의 결과에서 RGBD는 RGB의 early-fusion이고, 입력의 깊이 채널이다.
HHA는 수평간격, 지상으로 부터의 높이, 중력 방향으로 수직인 국소 표면의 각도를 embedding한 깊이이다.
RGB-HHA는 RGB와 HHAm의 예측을 합친 late fusion model이다.
NYUDv2는 Microsoft Kinect에 의해 수집된 RGB-D dataset이다.
그것은 Gupta et al에 의해 40개의 semantic segmentation task 클래스로 나뉘어지고 pixelwise labels이 된 1449 RGB-D images를 가지고 있다.
우리는 이를 795개의 훈련 이미지와 654개의 테스트 이미지로 나누었다.
Table 4.는 여러 평가 방법으로 측정한 우리 모델의 성능이다.
처음으로 우리는 RGB 이미지들에서 수정하지 않은 FCN-32s를 훈련했다.
깊이 정보를 더하기 위해서, 우리는 모델이 4개 채널의 RGB-D input을 받도록 발전시켰다.(early fusion)
이것은 아마 모델이 의미있는 gadient를 전파하기 어렵기때문에 이점이 없다.
Gupta et al의 성공을 따라, 우리는 깊이에 대해 3차원 HHA encoding을 수행하고 이를 통해 네트워크를 학습시켰다.
그 뿐만 아니라, RGB와 HHA의 late fusion도 고려하였는데, 이는 각각의 네트워크가 마지막 layer에서 합쳐지는 것이다.
그리고 두개의 네트워크는 end-to-end로 학습된다.
마침내 우리는 16-strdie 버전의 late fusion 네트워크로 업그레이드 할 수 있었다.
SIFT Flow는 33 semantic categories와 3개의 geometric categories로 pixel이 라벨링된 2,688 images를 가진 dataset이다.
FCN은 라벨과 타입을 동시에 자연스레 학습할 수 있다.
우리는 a two-headed version의 FCN-16s으로 semantic and geometric prediction layers and losses를 학습했다.
각각의 모델들은 빠르고 잘 두개의 task들을 학습했다.
2,488 training와 200 test images로 나눈 Table 5.의 결과는 두개의 task 모두에서 sota 성능을 보여준다.

Table 5.
이는 SIFT Flow 데이터에 대한 (중간)class segmentation, (오른쪽) geometric segmentation 결과이다.
Tighe은 파라미터가 없는 transfer method이다.
Tighe 1은 SVM의 예시이고, Tighe 2는 SVM + MRF의 예시이다.
Farabet은 (1)균형 클래스 샘플 또는 (2) 자연적 주파수 샘플에서 훈련된 multi-scale convnet 이다.
Pinheiro는 multi-scale, recurrent convnet, denoted RCNN3이다.
geometry에 대한 평가 지표는 pixel accuracy이다.

Figure 6.
Fully convolutional segmentation nets는 PASCAL에서 sota 성능을 보여주었다.
왼쪽 열은 우리의 가장 좋은 성능을 보이는 FCN-8s의 출력값이다.
두번째 열은 이전 sota system인 SDS의 출력값이다.
첫번째 행의 복구된 미세한 구조물, 두번째 행의 밀접하게 상호 작용하는 물체를 분리하는 능력, 세번째 행의 장애물에 대한 견고성(rosbusness)에 대해 주목해라.
네번째 열은 실패 케이스이다. 네트워크가 구명조끼를 사람으로 인식했다.
6. Conclusion
Fully convolutional networks는 현대 분류 convnet들이 special case인 경우에 풍부한 종류의 모델이다.
이를 고려하면, 분류 네트워크를 segmentation으로 확장하는 것은 그리고 multi-resolution layer combinations으로 발전시키는 것은 sota를 극적으로 향상시키는 동시에 모델을 심플하게 만들고, 학습과 추론을 빠르게 만들 수 있을 것이다.
'Naver boostcamp -ai tech > Paper review' 카테고리의 다른 글
| CGAN - 논문 리뷰 (0) | 2022.10.19 |
|---|---|
| GAN - 논문 리뷰 (1) | 2022.10.19 |
| Batch Normalization - 논문 리뷰 (0) | 2022.09.28 |


